DataComponent Element¶
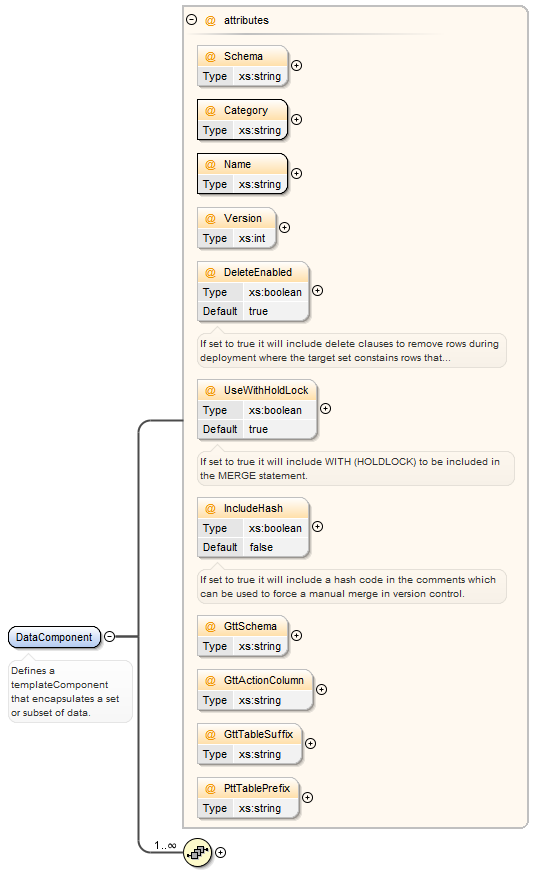
| Attribute | Description |
|---|---|
| Schema | Specifies the default schema to use, this is optional. |
| Category | The is the name under which you wish to group this type of component. |
| Name | The name is what will be used to display the component name with DATASTAR and will be also used as the file name (with a .sql suffix). Then name can be a static value, however it is more likely that you will want to derive this value dynamically based on the data that is in your database. Therefore you can also specify a variable name that is resolved against the data returned in the dynamic query element. If using variables try and use something unique like ${filename} |
| DeleteEnabled | Optional and defaulted to "true", this flag allows you to turn off deletes statements from the generated scripts making them update or insert only. |
| IncludeHash | Optional and defaulted to "false", this flag will generate a "PRINT" statement at the end of the script with a SHA256 calculated hash value. This can be used to verify the version of the script, it can also be used to force a manual merge for conflicts when merging files, avoiding automatic merge conflict resolution. |
| PttTablePrefix | This is only applicable to Oracle, DATASTAR uses temporary tables to determine what has changed and apply inserts, updates and deletes. If your tables do not contain BLOB/CLOB columns and you are on version 18c or higher you can use Private Temporary Tables. The PRIVATE_TEMP_TABLE_PREFIX initialisation parameter, which defaults to "ORA$PTT_", defines the prefix that must be used in the name when creating the private temporary table. To use Private Temporary Tables set this attribute to the prefix in use on your database.. |
| GttSchema | This is only applicable to Oracle where you need to use Global Temporary Tables. DATASTAR uses temporary tables to determine what has changed and apply inserts, updates and deletes. In SQL Server this is handled via table variables within the scripts themselves, however Oracle does not support this concept and therefore Global Temporary Tables must be used. DATASTAR has an option to create these tables for you, however it is recommended that you keep these separate from your main database schema. The GttSchema is the name of the schema in Oracle where you want to have the Global Temporary table. |
| GttActionColumn | This is only applicable to Oracle where you need to use Global Temporary Tables, the Global Temporary Tables have an action column which helps DATASTAR determine the action to take (i.e insert, update, delete or do nothing). Normally you do not need to specify this but in the event that it conflicts with an existing column name in your target table then you can override the Global Temporary Table column name using this attribute. |
| GttTableSuffix | This is only applicable to Oracle where you need to use Global Temporary Tables, it is recommended that you apply a suffix so that the Global Temporary Tables have a version for example "_V1", this will ensure that you can support multiple versions of the templates should you decide to change them. |
| Version | Currently only used for SQL Server templates. Version 2 templates do not include the DELETE in the MERGE statement, instead these are moved to the end of the script and handled in reverse order so that the chance of hitting a foreign key constraint on delete in minimized. Add this option can negate the need for using before and after scripts to enable and disable constraints. |
Option Element¶
The Option element is optional and can be specified zero or more times. It is used to configure SQL options and is included in the generated script.
Using Microsoft SQL Server you can specify any valid SQL Options, for example:
<Option Name="ANSI_WARNINGS" Value="OFF"/>
<Option Name="NOCOUNT" Value="ON"/>
<Option Name="DATEFORMAT" Value="ymd"/>
<Option Name="IncludeDatabaseContext" Value="true"/>
Using Oracle you should include SERVEROUPUT so that logging output is generated, for example:
Option Element when specified as a child of the Table Element
The Option element is optional and can be specified zero or more times. It is used to configure SQL options and is included in the generated script. The Option element under Table cannot be used with Oracle.
Using Microsoft SQL Server you can specify any valid SQL Options that apply to the table, for example:
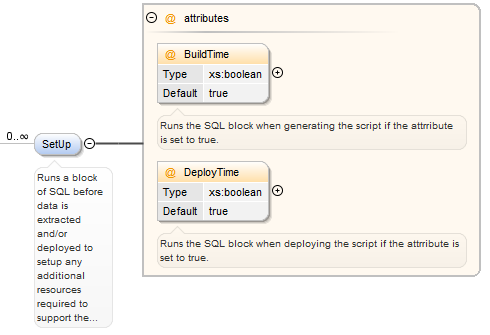
SetUp Element¶
The SetUp element is optional, if this is populated it should be specified in a CDATA section. This option allows you to include a block of custom SQL, this can be useful if you want to populate a temporary table that you later want to reference in the component. There are two attributes which control whether the script is run at "BuildTime" i.e. when generating the script, and/or at "DeployTime" in which case the script will be embedded in the generated component.
TempTable Element¶
Occasionally it is useful to reference temporary tables, for example you might want to use a temporary table as a filter or lookup that is referenced with the component definition. DATASTAR is able to determine the table and column definitions for standard tables, however for temporary tables the table definition must be specified. This structure allows you to specify the temporary table name, columns and types so that DATASTAR can reference this information.
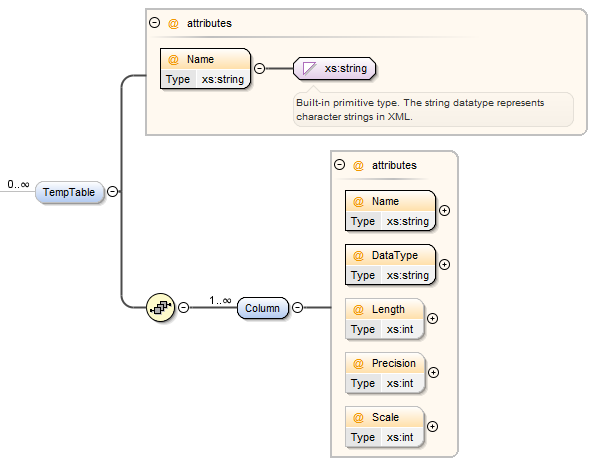
Define the name of the temporary table you are using in the "Name" attribute of the table, for SQL Server this will be prefixed with "@" for table variables and "#" for temporary tables. If using Oracle these will be pre-defined as Global Temporary Tables, as such it should not be necessary to defined these tables here as this is specifically for dynamic tables created within session scope.
| Attribute | Description |
|---|---|
| Name | The name of the column. |
| DataType | The data type as defined in the database do not include the length or precision. |
| Length | The length of the column used for alphanumeric data types. |
| Precision | The precision of the column used for numeric data types. The maximum total number of decimal digits that will be stored, both to the left and to the right of the decimal point. |
| Scale | The scale of the column used for numeric data types. The number of decimal digits that will be stored to the right of the decimal point. |
Table Element¶
The Table element is specified for each database table that is to be included in the generated script.
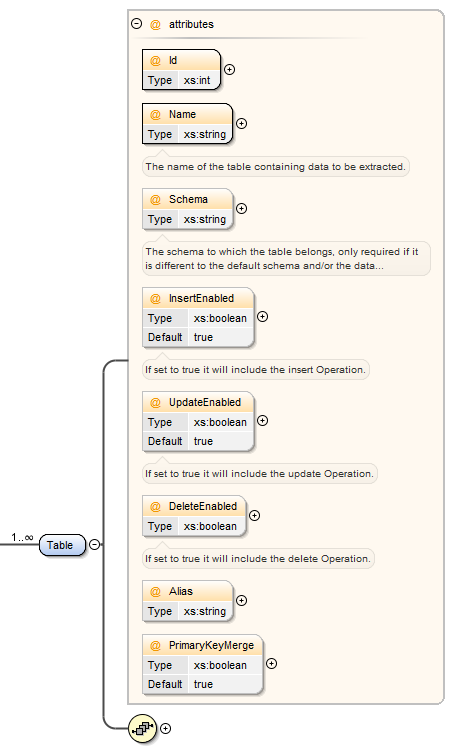
| Attribute | Description |
|---|---|
| Id | A unique identifier for the table reference as a numeric value. This attributes serves two purposes, firstly it controls the order in which the tables appear in the script, secondly it allows you to reference the same table multiple times within the same script. This feature means that you can include parent child relationships within the same script on the same table. |
| Name | The name of the table as defined in the database. |
| Schema | Optional, only required if you want to reference a table in a different schema from the default configure at the component level. |
| InsertEnabled | If you specifically don't want the generated scripts to insert data then this can be turned off by setting the value to false. The generated script will then exclude any insert operations on the table. |
| UpdateEnabled | If you specifically don't want the generated scripts to update data then this can be turned off by setting the value to false. The generated script will then exclude any update operations on the table.There are some other scenarios whether updates will be excluded automatically for example join tables where all the columns make up the primary key. |
| DeleteEnabled | If you specifically don't want the generated scripts to delete data then this can be turned off by setting the value to false. The generated script will then exclude any delete operations on the table. Note that this setting is ignored if you specifically generate a delete script. |
| Scale | The scale of the column used for numeric data types. The number of decimal digits that will be stored to the right of the decimal point. |
| Alias | DATASTAR will automatically generate an alias for tables within the scripts that get generated. This can be overridden if required to use a pre-defined alias. If using this option you should be careful to ensure that the alias doesn't conflict with other tables aliases. |
| PrimaryKeyMerge | By default DATASTAR will merge data (that is decide on whether to insert, update or delete data) using the primary key that has been defined for the table. This is the recommended setting as DATASTAR will resolve transient key values during execution of the script and therefore in nearly all circumstance this will be the natural key on which to merge. The feature can be disabled in which case DATASTAR will merge data using the alternative key. Use this option with care as it could cause unique key constraint violations or result in duplicate rows. |
Child Elements
The Table element is configured with the following child elements:
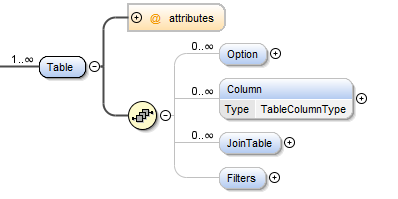
Column Element¶
The column element allows you to configure any special behavior that you require for a column. You do not need to define every column here as DATASTAR will automatically determine the columns that belong to the table. However there are cases where you might want some different behavior such as using a default value, or when using key generator.
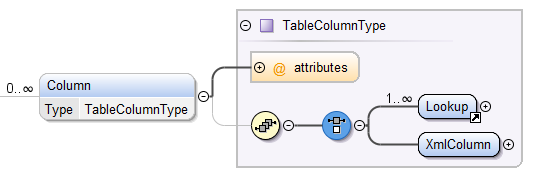
| Attribute | Description |
|---|---|
| Name | The name of the column as defined on the database. |
| PrimaryKey | You need to tell DATASTAR which columns to use as the primary key. The current version will not determine this from the database automatically, this provides some flexibility as sometimes tables are created without primary keys or in rare cases you might want to use a different primary key from that defined on the table. This can be useful when working with third party database tables where the key may be incorrectly defined on the database. Note: Make sure you list each column element that makes up the primary key. |
| AlternativeKey | If you are using generated key values for example using a stored procedure to generate key values or a database sequence then these generated or transient values will be different between database environments. In this case DATASTAR requires an alternative consistent key so that it can resolve the transient values when the script is executed. |
| InsertExclude | There are occasions when you do not want a columns value to be inserted, for example when using computed columns, database defaults or identity columns. In this case you should define the column and set the InsertExclude attribute to "true". |
| UpdateExclude | There are occasions when you do not want a columns value to be update, for example if you have a CREATED_DATE column, it is unlikely that you want to have this value updated. In this case you should define the column and set the UpdateEclude attribute to "true". |
| UpdateTrigger | DATASTAR scripts are designed so that they only perform an insert, update or delete operation when a difference is detected. You may want to exclude certain columns from triggering an update for example columns such as UPDATED_TIME or UPDATED_BY should be included in the update operation but should not in themselves trigger the update to occur. Setting this attribute to "false" will exclude the column from causing an update to occur. |
| CurrentDate | Only applicable to date or time based columns. The valid values for this attribute if specified are Date which will set the column to a date value (excluding time), Time which will set the column to a time value (excluding date) and DateTime which will set the column to a date and time value. The current date will use the underlying date time functions on the database, for SQL Server this uses GETDATE() and for Oracle either CURRENT_TIMESTAMP or CURRENT_DATE |
| Value | if you want to always set a column to a specific value then you can set the value here. This also supports SQL functions such as SYSTEM_USER, to use a SQL function it must be prefixed and suffixed with a '%' character, for example "%SYSTEM_USER%". |
| Default | This attribute is designed to be used with the Increment attribute. It allows you to specify a starting value for the increment. |
| Increment | This attribute allows you to implement a record version without having to implement a trigger. Each time the table is updated the value will be incremented by the amount specified. |
| Transient | These are columns where the value is likely to be different between environments, for example if you are using a generated key based on a sequence, it is likely that the value will be different between your development, test and production environments. If you mark a column as being transient it should either be a primary key column, where you have specified an alternative key on the table, or provided a Lookup child element with details about how to resolve the columns value. |
| Generator | This defines the statement that needs to be executed in order to determine the next value from the key generator. For example you can specify a stored procedure or sequence see the examples below:
|
| CaseSensitive | This only applies to SQL Sever and alphanumeric columns where the column is being used to match with another key value, for example you might want to force primary key matches to be case sensitive. Set to true to force a case sensitive match, by default this will use the collation COLLATE Latin1_General_CS_AS - you can specify a different collation using the Collation attribute. |
| Collation | See the CaseSensitive attribute. |
| DataType | Only required if you want to override the data type as defined in the database. |
| Length | Only required if you want to override the data type as defined in the database. The length of the column used for alphanumeric data types. |
| Precision | Only required if you want to override the data type as defined in the database. The precision of the column used for numeric data types. The maximum total number of decimal digits that will be stored, both to the left and to the right of the decimal point. |
| Scale | Only required if you want to override the data type as defined in the database. The scale of the column used for numeric data types. The number of decimal digits that will be stored to the right of the decimal point. |
| SortOrder | You can control the order in which the data included in the generated scripts, specify the sort order by giving it a sort index for example "1" would mean that the data will be sorted by this column first. |
| SortDirection | You can control the sort order direction by specifying "Asc" for ascending or "Desc" for descending. |
Lookup Element¶
In many cases a table will contain a foreign key reference. Where a foreign key is a logical business key then typically it would not need to be resolved. However in many cases a foreign key will be an identity value from the parent table which will differ between environments, in this case it is necessary to provide a Lookup so that the foreign key reference can be resolved during deployment. It is not necessary for a foreign key to be defined at the database level, all that is required is for the relationship to exist. In fact the column doesn't have to exclusively reference a single parent, it can contain a mixture of foreign key references and non transient data, even resolving references that may span more than one table.
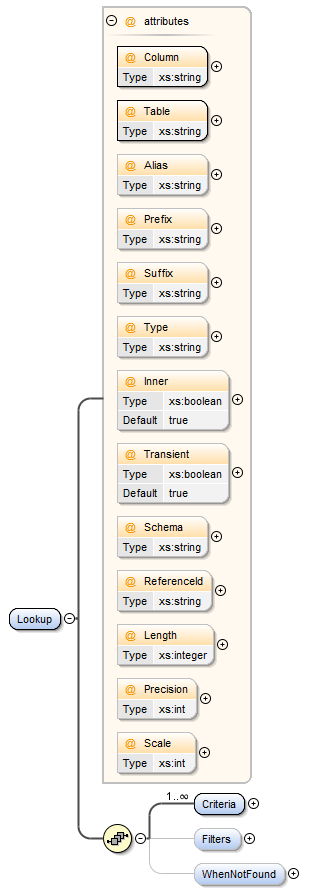
| Attribute | Description |
|---|---|
| Column | The name of the column on the table that is being used for the lookup (i.e. this will normally be the column on the table being referenced via the foreign key) |
| Table | The name of the table that is being used for the lookup (i.e. this will normally be the table being referenced via the foreign key) |
| Prefix | If the data contains a prefix that does not exist on the parent table, for example an account number prefixed with "A12345678" but the parent table only contains the numerical part, then specify the Prefix="A" will allow that data to be resolved. |
| Suffix | If the data contains a suffix that does not exist on the parent table, for example an account number suffixed with "12345678A" but the parent table only contains the numerical part, then specify the Suffix="A" will allow that data to be resolved. |
| Type | The data type as defined in the database do not include the length or precision. |
| Length | The length of the column used for alphanumeric data types. |
| Precision | The precision of the column used for numeric data types. The maximum total number of decimal digits that will be stored, both to the left and to the right of the decimal point. |
| Scale | The scale of the column used for numeric data types. The number of decimal digits that will be stored to the right of the decimal point. |
| Schema | Optional, only required if you want to reference a table in a different schema from the default configure at the component level. |
| ReferenceId | DATASTAR provides the ability to find other data components that you have defined so that for any component you can either find the lookup that it uses and/or find where the component is used. Please refer to the |
| Transient | Typically the referenced value will be transient (i.e. the value should always be looked up), a transient value will mean the column value will be null in the generated script as it should be resolved during deployment. This is the default behavior if you do not specify this attribute. However sometimes you may want the source value to be included in the generated script if the lookup was not resolved, this can be achieved by setting the value to "false" in this case DATASTAR will check when the script is generated whether the reference can be resolved, and if it can't then the value will be included in the script, therefore only resolved references will have the value set to null (to be resolved when the script is deployed). |
| Inner | The default behaviour is to resolve references using an INNER JOIN, this can be overridden by including this attribute and setting the value to "false" in which case the lookup will be generated using a LEFT JOIN. |
| Alias | Currently only supported for Oracle, specifies the lookup column alias which acts as a prefix for the Global Temporary Table columns that are added to support lookups. |
| As | Currently only supported for Oracle, when specified if allows the template to control the name of the Lookup column referenced in the script. This is only required in rare occasions where there might be a conflict on column names, for example where the criteria references the same column name that is in the lookup. |
Criteria Element¶
A lookup must use an alternative key to resolve the foreign key during deployment. This is know as the Criteria, the element should be specified for each column that makes up the alternative key.

| Attribute | Description |
|---|---|
| Column | The name of the alternative key column on the table that is being used for the lookup. |
| Length | Note this is only relevant when the lookup is defined in an XML column. |
| Nullable | Default "true" causes the lookup to match on string types so that it can also match null values. If you need to match on numeric values then set the value to "false". |
Filters Element¶
In a more complex scenarios you could have a column which contains a mixture of values and identifiers, the values need be migrated and the identifiers resolved. Adding further complexity the identifiers themselves might reference several tables (i.e. containing foreign keys to several tables all of which need to be resolved). DATASTAR handles this by using multiple lookups each with optional filters to identify the values to be resolved via a look up. Filters only apply to the source data to identify the values that should be looked up by the criteria specified.
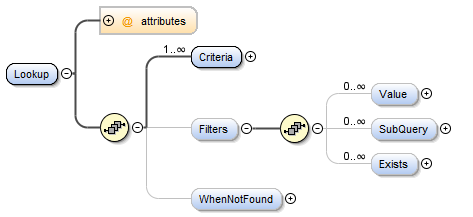
Value Filters
You can specify value filters to filter on specific values or conditions, such a the value being numeric.
SubQuery Filters
You can specify sub-query filters to filter on specific a source table column being in sub-query result set.
Exists Filters
You can specify a query filters to filter on data existing in the given query.
SubQuery Element¶
The SubQuery element provides the ability to filter on data contained where a columns value is in the the given sub-query.

| Attribute | Description |
|---|---|
| Column | The name of the column on which the sub-query is being applied. |
| Operator | The operator to be used, valid values include
|
| DataType | If the data types are different it is possible to provide a conversion data type, DATASTAR will attempt to cast the data to this type to avoid errors when joining data. |
| Length | The data type length, if applicable. |
| Precision | The data type precision, if applicable |
| Scale | The data type scale, if applicable |
| DeployTime | Specifies whether to apply the filter at deploy time. |
Value Element¶
The Value element provides the ability to filter on data with the given value attributes.
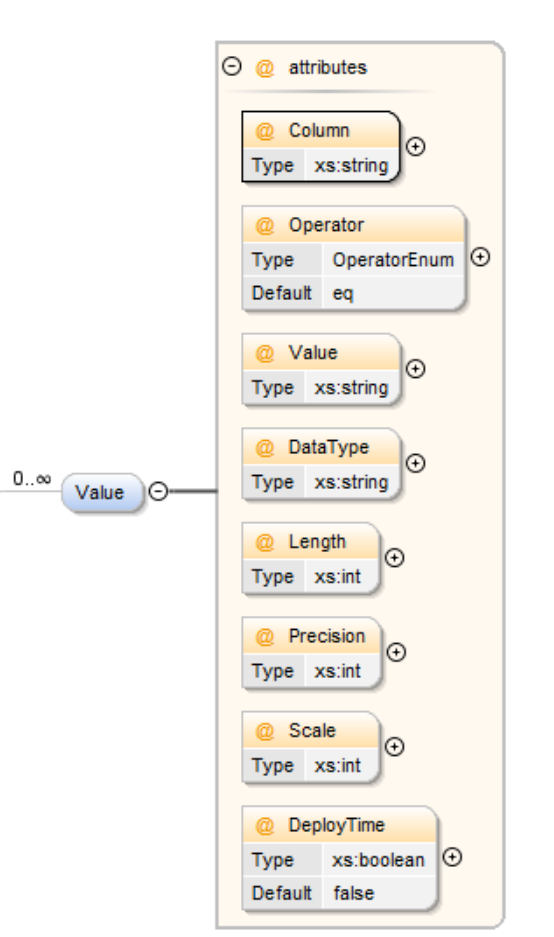
| Attribute | Description |
|---|---|
| Column | The name of the column on which the filter is being applied. |
| Operator | The operator to be used, valid values include
|
| Value | This can either be a literal value, or alternatively you can use a variable defined in your dynamic query. |
| DataType | If the data types are different it is possible to provide a conversion data type, DATASTAR will attempt to cast the data to this type to avoid errors when joining data. |
| Length | The data type length, if applicable. |
| Precision | The data type precision, if applicable |
| Scale | The data type scale, if applicable |
| DeployTime | Specifies whether to apply the filter at deploy time. |
Exists Element¶
The Exists element provides the ability to filter on data where a data exists in the given query.
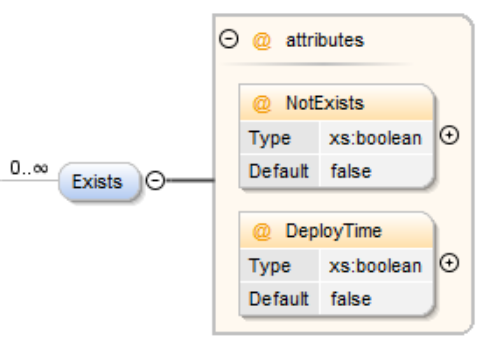
| Attribute | Description |
|---|---|
| NotExists | Optional attribute to turn the exists into a not exists condition. |
| DeployTime | Specifies whether to apply the filter at deploy time. |
WhenNotFound Element¶
The WhenNotFound provides the ability to error, or write a warning message when a look up is not resolved during deployment. The valid "Action" values are:
- None - ignore when look up is not resolved (the default)
- Assign - assign the value that is in the field (currently only supported for Oracle)
- Warn - generate a warning message in the output generated by the script
- Error - generate an error and stop execution of the script.
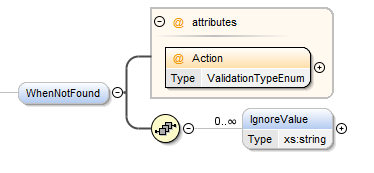
In some circumstances there maybe a default value which will not be resolved during lookup but is an allowed value. This is handled via the "IgnoreValue" element which can repeated for all the values that should be ignored.
XmlColumn Element¶
It is common for a database table to contain XML. In normal circumstances there is no need to define an XML column in DATASTAR if you just want it updated / inserted in the target environment. However consideration should be given to the size of the XML data as DATASTAR is designed to generate scripts and for very large XML documents it may not be appropriate to generated this into a script.
In other scenarios the XML data may contain foreign key references, which need to be resolved during deployment in the same way that Lookup columns are resolved, or even nested XML fragments with foreign key references. DATASTAR is able to handle this in a similar way to Lookup columns, except that you provide an XPath query to locate the identifiers to resolve.
When you generate a script the alternative key(s) for the lookup are determined. These alternative key values are converted into a single hash value which is substituted into the XML attribute(s) or element(s) identified via the XPath query. The generated will reverse these values during deployment to identify the alternative keys and look up the values so that the correct foreign keys can be inserted into the XML document. If you view the script you will see the identifiers that have been resolved in a comments section within the script. See below for an example:
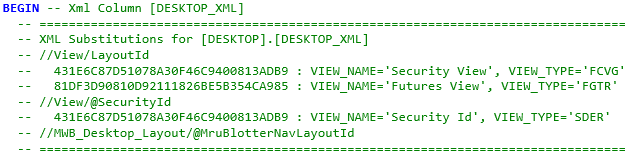
In processing XML the "Xml Declaration" is often removed by database XML processors, if this occurs and you want it retained in the Xml you can provide the Xml Declaration to use in Declaration attribute. The content of the declaration attribute must be escaped using XML escape sequences such an < for < and > for > characters.
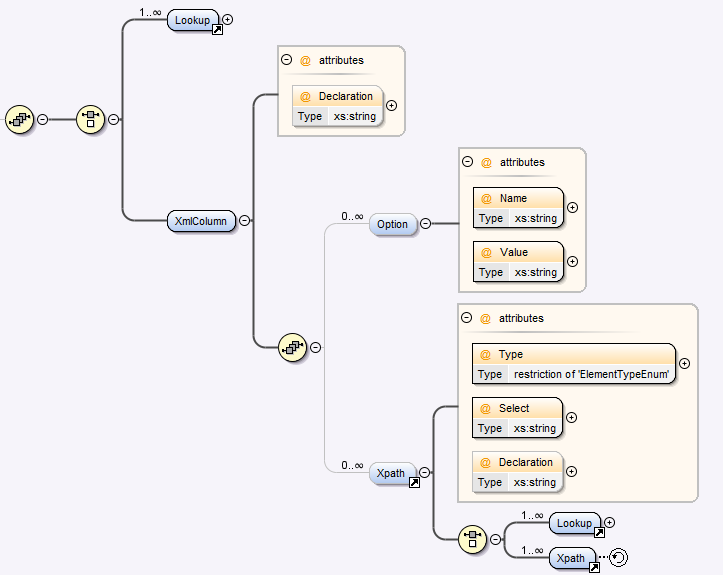
Xpath Element¶
- The Xpath element should be repeated for each XPath that you wish to resolve. The Type attribute should be specified so that DATASTAR to indicate if the XPath will resolve to an attribute or an element. The valid values are "Attribute" or "Element".
The Select attribute should be a valid Xpath statement, for example:
The Declaration attribute allows you to apply and XML Declaration to the XML. The content of the declaration attribute must be escaped using XML escape sequences such an < for < and > for > characters.
In some circumstances there maybe a default value which will not be resolved during lookup but is an allowed value. This is handled via the "IgnoreValue" element which can repeated for all the values that should be ignored.
JoinTable Element¶
In more complex scenarios your data may span more than one table, in which case you will want to define the relationship to these other tables so that the script only contains the related data. This is done by specifying a JoinTable element.

| Attribute | Description |
|---|---|
| ReferenceId | The id of the table this table is related to using the identified specified in the table id attribute. |
| Relationship | The relationship to the parent table:
|
| FilterOnly | You can specify the join as only being used to filter the data. |
| BruteForce | Defaults to "false", if specified it will automatically force the join based on the id that was resolved in the parent table. Use with care as it assumes that the script will only every contain a single parent id. |
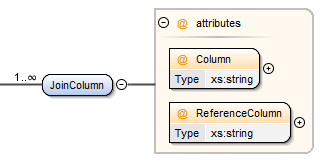
JoinColumn Element¶
You should specify how the tables are joined using the Column and ReferenceColumn attributes.
| Element | Description |
|---|---|
| Column | The name of the column on which the join is being applied. |
| ReferenceColumn | The name of the column on the related table on which the join is being applied. |
Filters Element [Table]¶
Filters can be applied to the table so that the script only includes the desired set of data.
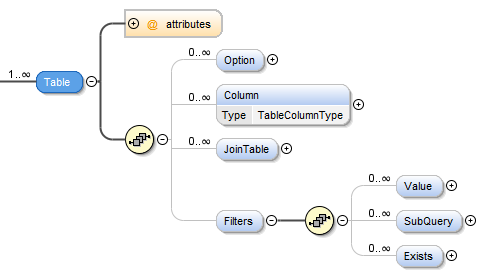
| Element | Description |
|---|---|
| Value | You can specify value filters to filter on specific values or conditions, such a the value being numeric. |
| SubQuery | You can specify sub-query filters to filter on specific a source table column being in sub-query result set. |
| Exists | You can specify a query filters to filter on data existing in the given query. |
SubQuery Element [Filters]¶
The SubQuery element provides the ability to filter on data contained where a columns value is in the the given sub-query.
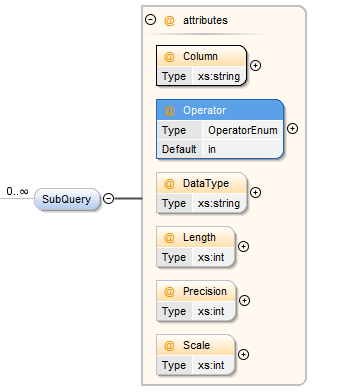
| Attribute | Description |
|---|---|
| Column | The name of the column on which the sub-query is being applied. |
| Operator | The operator to be used, valid values include
|
| Value | This can either be a literal value, or alternatively you can use a variable defined in your dynamic query. |
| DataType | If the data types are different it is possible to provide a conversion data type, DATASTAR will attempt to cast the data to this type to avoid errors when joining data. |
| Length | The data type length, if applicable. |
| Precision | The data type precision, if applicable |
| Scale | The data type scale, if applicable |
Teardown Element¶
The Teardown element is optional, if this is populated it should be specified in a CDATA section. This option allows you to include a block of custom SQL, this can be useful if you want to delete a temporary table or apply a custom update during execution of the script. There are two attributes which control whether the script is run at "BuildTime" i.e. when generating the script, and/or at "DeployTime" in which case the script will be embedded in the generated component.

The scripts that are generated by DATASTAR include table variables that provide information about the actions that that take place during deployment. Every table will have a @
<Teardown BuildTime="false" DeployTime="true">
<![CDATA[
UPDATE TGT
SET TGT.PASSWORD_EXPIRY_DATE = GETDATE() -1
FROM [dbo].[USER_DETAILS] TGT
INNER JOIN @USER_DETAILS_CHANGE_SUMMARY CS
ON CS.USER_CD = TGT.USER_CD
AND CS.CHANGE = 'INSERT';
IF @@ROWCOUNT > 0 PRINT 'Password expiry date reset for new user ${user.name}';
]]>
</Teardown>
DynamicQuery Element¶
The dynamic query allows the Data Component definition to be used as a template. If being used to generate multiple scripts that DynamicQuery should contain a CDATA section with a query that returns a row per script. The columns that are returned should be given a variable name such as ${name} and then your template can contain these variables.
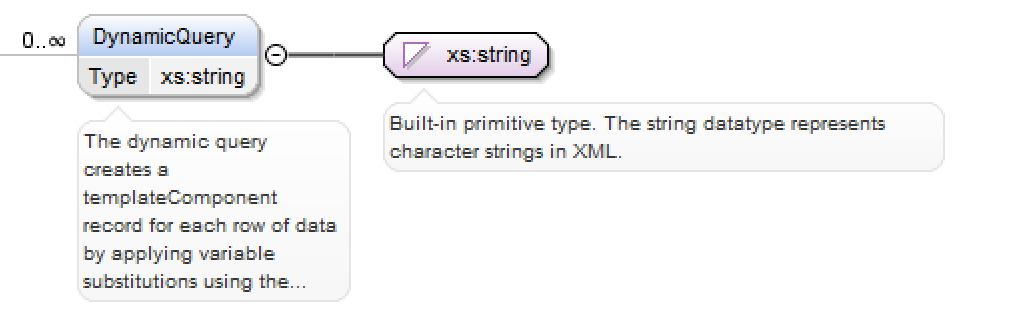
For example in my template I could have a Data Component defined <DataComponent Category="views" Name="${name}" DeleteEnabled="true"> and in my DynamicQuery I would provide a CDATA section with a column that returned the file name and any other variables that I needed to use. It is also a good idea to escape the data returned if you know it might contain characters that would not be valid.
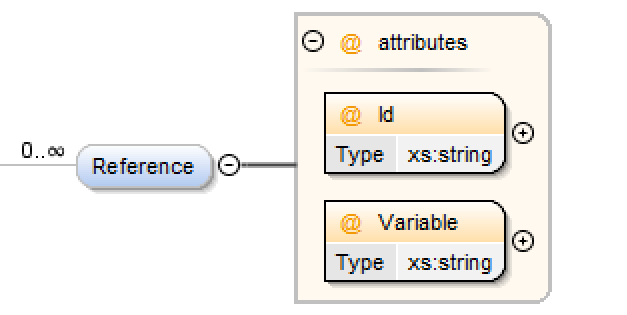
Reference Element¶
When defining your data components you may need to add Lookup elements to certain columns to resolve transient identifiers when deploying to a target environment. However without knowing which components are being referenced it would be difficult to determine whether you had generated all the necessary components, for example the lookup might reference a new record and therefore you would also want to generate that component. DATASTAR provides a facility to allow you to easily find references from the Code Generation view provided you provide it with the information so that it can resolve the record key with your components, this is necessary as different levels of granularity may be implemented.
The definition is relatively straight forward, first you need to tag the Lookup elements with a reference id, in the example below we are looking up the EXAMPLE_ID column on a table called EXAMPLE_PARENT to get the ID column value using the NAME column as an alternative key. To support the find references feature we need to tag this lookup with a ReferenceId attribute.
<Column Name="EXAMPLE_ID" Transient="true">
<Lookup Table="EXAMPLE_PARENT" Column="ID" Transient="false" ReferenceId="example">
<Criteria Column="NAME"/>
</Lookup>
</Column>
The next step is to tell DATASTAR how to map the EXAMPLE_ID values to your components that you have configured. This is configured in in the Reference element. The Id attribute should match the ReferenceId tag that you have applied to your Lookup elements. The content of the Reference element must be a query that can be used to look up the component using the key of the lookup element, the key will be injected into the query you provide using the variable name from the Variable attribute, therefore your query must contain this variable in the predicate.
Example:
<Reference Id="example" Variable="${LookupKeyQuery}">
<Query>
<![CDATA[
select distinct 'example-category' as Category,
[name] as 'Name' from PARENT where ID in (${LookupKeyQuery})
]]>
</Query>
</Reference>
Deployment Element¶
The Deployment element is used when you package up scripts to be deployed within a release. A component within a package may be order sensitive for example you may need to deploy component A before component B. DATASTAR will sequence the items contained in your deployment using the Weight. In some cases it is necessary to run a script before the components are deployed and another script afterwards, for example a script to disable constraints and then a script to enable them afterwards. This is handled via the Script element as shown in the example.
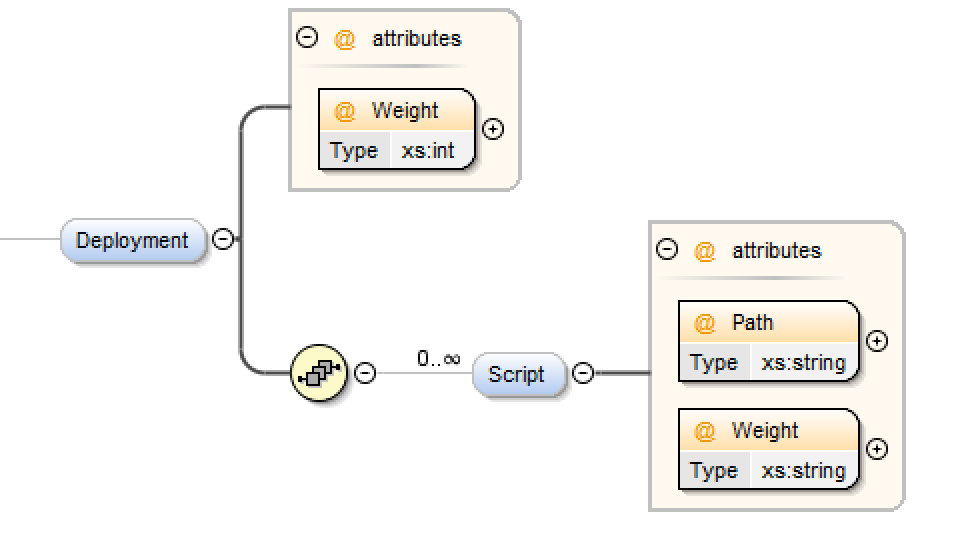 Example:
Example:
<Deployment Weight="1500">
<Script Path="templates/scripts/views-constraints-disable.sql" Weight="-1"/>
<Script Path="templates/scripts/views-constraints-enable.sql" Weight="+1"/>
</Deployment>
The path is relative from your workspace and should be under source control as during deployment DATASTAR will identify the version from your source control system. Not you can give a + or - value which effectively gives it a weight relative to the Deployment element Weight.